
V laboratoriju smo se odločili, da strojno prevedemo vzorec luknjanega traku, ki ga je pred leti Računalniškemu muzeju podaril dr. Peter Scherber.
http://www.racunalniski-muzej.si/obisk-dr-petra-scherberja/
Računalniška tehnologija je že zelo zgodaj začela prodirati na področje raziskav jezika, prevajanja in podobno. Prve poskuse s strojnim prevajanjem v Jugoslaviji so izvedli že nekje konec petdesetih na Inštitutu za eksperimentalno fonetiko v Beogradu. Takrat nov računalnik domače izdelave CER-10 so želeli usposobiti, da bi deloval kot robot prevajalec. V ta namen so naredili statistično obdelavo srbo-hrvaščine in izdelali ustrezen slovar za računalnik.
Slovar Prešernovega pesniškega jezika
Tudi nemški slovenist, prevajalec, literarni raziskovalec Dr.Peter Scherber se je v okviru svojih slovenističnih raziskav v sedemdesetih odločil, da poskusi s takrat dostopno računalniško tehnologijo izdelati slovar pesniškega jezika Franceta Prešerna. V ta namen je moral najprej prenesti Prešernova besedila na luknjane trakove. Nato pa jih je lahko uporabil za računalniško analizo leksikalnega gradiva z vidika konkordance in pogostnosti, ter izdelavo slovarja. Obdelavo podatkov je avtor izvedel na računalniku UNIVAC 1108, ki so ga imeli v Društvu za znanstveno obdelavo podatkov v Göttingenu.
Njegov namen je bil podati bralcu Prešernovih del kar največ informacij o pesnikovem jeziku. Je pa takrat predvsem tudi prikazal, na kakšen način in koliko si raziskovalci na tem področju že lahko pomagajo z novo računalniško tehnologijo in metodologijo. Rezultati so bili vsekakor spodbudni, četudi je samo delo avtorja kasneje prejelo precej kritičen pregled Stanislava Suhadolnika (LINK).

Slovar Prešernovega pesniškega jezika je v slovenščini izdala založba Obzorja leta 1977. Slovar najprej v abecednem zapovrstju podaja položaj in obliko posameznih besed/gesel v kontekstu določenega verza, nato pa ugotavlja, kako pogosto se posamezna beseda pojavlja v delih.
Izbira programske opreme
V laboratoriju Računalniškega muzeja smo našli več programskih rešitev za pomoč pri dekodiranju vsebine luknjanega traku. Obstajajo sicer projekti za izdelavo lastnega bralnika luknjanih trakov, na primer s pomočjo 3D tiskalnika, vendar ti zahtevajo nekaj sestavljanja in izdelavo vezja. Za naš projekt pa smo iskali lažjo, bolj praktično rešitev.
Krajše primerke trakov je tako možno enostavno optično digitalizirati, bodisi poslikati, posneti ali poskenirati, in nato z ustrezno programsko opremo dekodirati. Za tak pristop smo se odločili tudi mi.

Našli smo dva programska paketa za dekodiranje traku iz slike.
Slednji je izgledal zelo obetaven, ker je njegova koda preprosta in javno objavljena. Punched Tape Scanner smo uspešno prevedli in zagnali, se naučili kako se uporablja in prilagaja. Zgrajen je okrog klasične odprte knjižnice za strojni vid OpenCV in je zelo preprosto in učinkovito napisan, da ga lahko razume tudi nekdo, ki ni strokovnjak za področje strojnega vida.
Strojno prevajanje luknjanega traku
Prvi pristop za digitalizacijo luknjanega traku se ni obnesel – trak smo enostavno vlekli prek temne podlage in to posneli na videu. Iz videa smo nato želeli iztrgati posamezne sličice, vendar se je izkazalo da so posnetki preveč popačeni. Težave sta algoritmu programa, ki je bil razvit za obdelavo skeniranih slik, povzročala že na videz zanemarljiv naklon slike in dejstvo, da luknjan trak ni bil povsem sploščen in poravnan s podlago. Zato smo se morali potruditi in po delih s scannerjem poskenirati celoten trak, da smo dobili slike v pravem merilu, velikosti in brez popačitev.
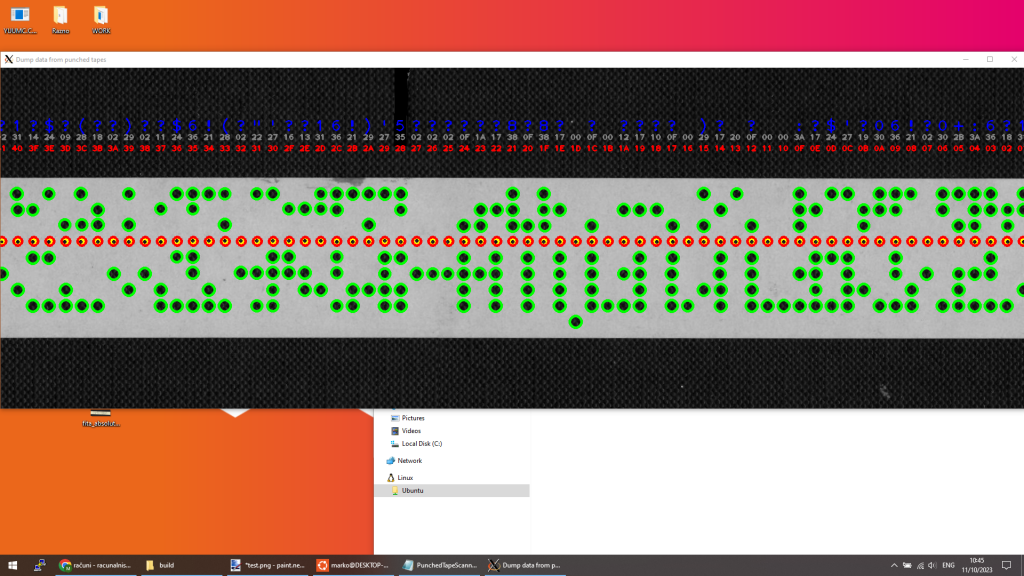
Gre za standarden 8-vrstični luknjani trak, ki se je pogosto uporabljal v računalništvu. Trak ima navpično razporejenih 3+5 luknjic, s pomočjo katerih so kodirani podatki. Vmes ima še eno vrstico manjših luknjic, ki služi za vodilo oziroma daje ritem bralniku traku.
Ko smo začeli s strojnim prevajanjem smo predvidevali, da so podatki kodirani v naboru ASCII, vendar pa se je izkazalo, da je uporabljen drug kodirni sistem. Informacije o uporabljenih napravah in kodirnem sistemu smo iskali v knjigi avtorja, hkrati pa poklicali na pomoč tudi skupnost na naših socialnih omrežjih.

Avtor dr. Peter Scherber je za vnos podatkov leta 1976 uporabil luknjalnik IBM Supertyper 8500 in različico kodiranja Binary-coded digital interchange code (BCDIC), ki se je pogosto uporabljala na zgodnjih računalnikih. Dekodirno tabelo smo po zaslugi Nejca Bertonclja našli tudi v priročniku za računalnik IBM 1620 (LINK, na strani 18)
Prevod luknjanega traku
Po strojnem prevajanju smo odkrili, da sta na traku Prešernovi pesmi ‘Prva ljubezen’ in ‘Slovo od mladosti’. Prevedli smo le osnovne znake-črke, na traku pa se skrivajo tudi znaki za naglase, oštevilčenje ipd. Zanimivo je, da se s tem razkrijejo tudi primeri, ko je avtor pri tipkanju naredil napako in sprožil ukaz 99 za brisanje trenutne vrstice – na traku so sledi tega seveda ostale, in so se tudi pokazale pri strojnem prevajanju.

Avtor je v svojem delu leta 1977 sicer ugotovil, da Prešernove Poezije zajemajo 3161 verzov z 16.878 različnimi besednimi oblikami, iz teh pa je izločil 2822 gesel. Največkrat se pojavljajo: beseda biti(1426), zaimek on(606), predlog v(376), zaimek jaz(307), veznik in(300).
..pripravil Marko Štamcar, vodja laboratorija.